
- Perché il monitoring tradizionale non basta nelle architetture distribuite
- Cos’è Elastic APM e perché il distributed tracing cambia le regole
- Come funziona il distributed tracing con Elastic APM (end‑to‑end)
- Cosa si vede in Kibana APM UI
- I vantaggi di Elastic APM per il business e l’operatività IT
- Integrazione di Elastic APM nello stack enterprise e OpenTelemetry
- FAQ
Elastic APM è una delle soluzioni più utilizzate per l’Application Performance Monitoring in ambienti moderni, distribuiti e cloud‑native. In architetture basate su microservizi, container e integrazioni esterne, monitorare solo CPU, memoria e uptime non basta più: serve comprendere come si comporta una richiesta lungo tutto il suo percorso, dal frontend al database.
Grazie al distributed tracing, Elastic APM permette di tracciare in modo end‑to‑end ogni transazione applicativa, correlando metriche, log ed errori in un unico contesto. Il risultato è una visibilità reale sulle performance applicative, utile non solo per risolvere incidenti più velocemente, ma anche per migliorare affidabilità, qualità del servizio e collaborazione tra team.
In questo articolo vediamo come funziona Elastic APM nel concreto, perché il tracciamento end‑to‑end cambia il modo di gestire le applicazioni e quali benefici operativi e di business può portare a organizzazioni IT complesse.
Perché il monitoring tradizionale non basta nelle architetture distribuite
Immaginate lo scenario: un cliente segnala una lentezza anomala su una transazione critica. Il responsabile IT avvia il giro delle squadre — backend, database, infrastruttura, integrazioni esterne. Ognuno risponde “da noi va tutto bene”. Il problema resta senza proprietario, i minuti passano e il cliente aspetta.
Questo non è un caso isolato: è la normalità nelle architetture distribuite moderne, dove un singolo flusso di business attraversa decine di componenti gestiti da team diversi. In questo contesto, la tradizionale gestione degli incidenti basata su metriche puntuali — CPU, RAM, uptime — non è più sufficiente.
È qui che l’observability smette di essere un concetto accademico e diventa un requisito operativo concreto. E Elastic APM ne rappresenta uno degli strumenti più potenti e maturi sul mercato.
Cos’è Elastic APM e perché il distributed tracing cambia le regole
Elastic APM (Application Performance Monitoring) è uno dei moduli della piattaforma Elastic, che include anche funzionalità avanzate di log management e security analytics.
All’interno della Elastic Observability Stack, Elastic APM è il componente dedicato al monitoraggio delle performance applicative e al tracciamento end-to-end dei flussi di esecuzione. A differenza dei sistemi di monitoring tradizionali che osservano le risorse infrastrutturali, APM va un livello più in profondità: traccia l’esecuzione del codice, le chiamate tra servizi, le query al database e le interazioni con sistemi esterni — tutto in tempo reale.
Il concetto chiave è il distributed tracing. Ogni volta che un utente esegue un’azione — un login, un pagamento, una ricerca — viene generata una trace: una rappresentazione strutturata dell’intera catena di chiamate che quella richiesta ha innescato attraverso l’architettura. Ogni singola operazione componente la catena è uno span, con inizio, durata, metadati e relazione parent-child con lo span precedente.
Monitoring vs. Observability — la differenza che conta

Il distributed tracing è l’elemento che collega metriche, log e trace, fornendo il filo narrativo di ogni richiesta.
Elastic APM raccoglie questi dati attraverso agent leggeri, installati nelle applicazioni, che strumentano automaticamente i framework più diffusi senza richiedere modifiche al codice applicativo. I dati vengono poi inviati all’Elasticsearch cluster e visualizzati in Kibana, all’interno dell’APM UI dedicata.
Come funziona il distributed tracing con Elastic APM (end‑to‑end)
Seguiamo un esempio reale: un’operazione di consultazione del saldo su un’applicazione bancaria.
Il percorso di una richiesta
Cosa si vede in Kibana APM UI
La visualizzazione a cascata (waterfall view) mostra graficamente ogni span come una barra orizzontale, proporzionale alla sua durata, con indentazione che riflette la gerarchia parent-child.
In un’unica schermata il team può vedere:
- Quale servizio ha introdotto la latenza maggiore
- Quante volte è stata interrogata la stessa tabella (N+1 query problem)
- Se la latenza è costante o spike-driven (problemi infrastrutturali vs. applicativi)
- Eventuali errori con stack trace completo, correlati alla trace specifica
- Il contesto utente, session ID e custom attributes definiti dal team di sviluppo
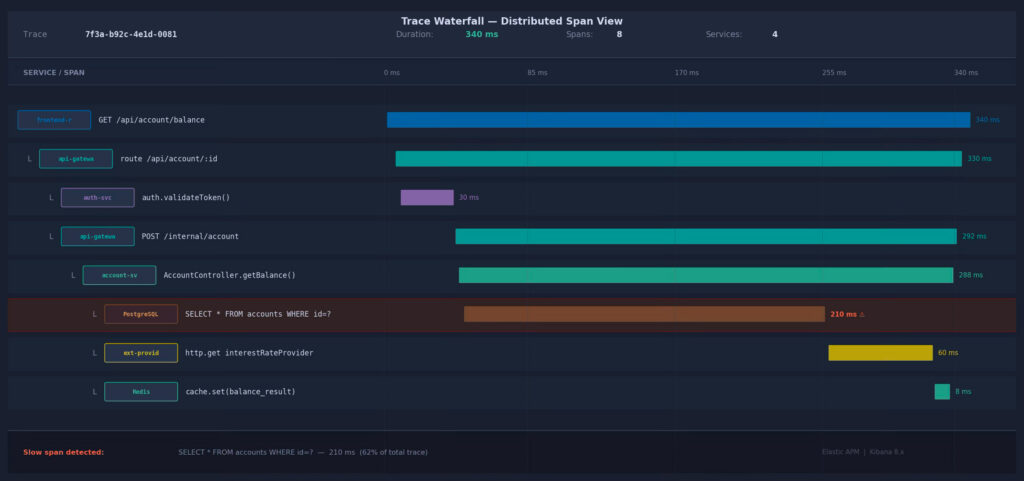
Kibana APM: visualizzazione a cascata (waterfall) di una trace con 8 span su 4 servizi. La query SQL evidenziata in rosso rappresenta il 62% della latenza totale
La stessa trace è automaticamente correlata con i log dei container coinvolti e con le metriche di sistema (CPU, memoria, GC) nel medesimo intervallo temporale — tutto senza dover eseguire join manuali tra sistemi diversi. Questa correlazione automatica è uno dei differenziatori principali di Elastic rispetto ad altri strumenti di tracing sul mercato.
I vantaggi di Elastic APM per il business e l’operatività IT
La tecnologia è il mezzo, i risultati operativi sono il valore. Ecco cosa cambia nell’organizzazione quando si adotta una strategia di observability basata su Elastic APM:
Un dato di riferimento
Organizzazioni che adottano pratiche strutturate di observability riportano in media una riduzione del 60–70% del tempo medio di risoluzione degli incidenti e una diminuzione significativa dei costi di escalation tra team (Fonte: DORA State of DevOps Report).
Nella pratica, per molte organizzazioni l’adozione di Elastic APM passa da un servizio gestito che ne garantisca progettazione, implementazione e continuità operativa.

SERVIZIO PROFESSIONALE
QUIPROAM – Servizio gestito di Application Monitoring
Scopri QUIPROAM, il nostro servizio gestito di Application Performance Monitoring basato su Elastic
Integrazione di Elastic APM nello stack enterprise e OpenTelemetry
Uno degli aspetti che rende Elastic APM adatto a contesti enterprise è la profondità dell’integrazione con stack tecnologici eterogenei e la flessibilità del modello di deployment.
Agenti disponibili
-
- Java, .NET, Node.js, Python, Go, PHP, Ruby — copertura pressoché totale degli stack enterprise
- Framework auto-instrumentati: Spring Boot, Django, Express, ASP.NET, Laravel e molti altri
- Supporto a RUM (Real User Monitoring) per il frontend browser e mobile (iOS/Android)
Compatibilità OpenTelemetry
Elastic APM supporta nativamente il protocollo OpenTelemetry (OTLP), lo standard CNCF per l’instrumentazione e la trasmissione di dati di observability. Questo significa che i team che hanno già investito in OpenTelemetry possono inviare dati a Elastic senza riscrivere l’instrumentazione esistente, proteggendo l’investimento tecnologico e garantendo portabilità futura.
Il vero valore dell’observability con Elastic APM non si misura solo nel tempo risparmiato durante un incidente: si misura nel passaggio da una gestione reattiva a una proattiva, capace di intercettare, comprendere e risolvere i degradi prima che impattino sull’esperienza utente o attivino processi di disaster recovery.
In architetture distribuite moderne, il distributed tracing non è un lusso tecnico ma l’unico strumento per mantenere visibilità e controllo su sistemi complessi.
Elastic APM trasforma la complessità da rischio operativo a vantaggio competitivo, abilitando decisioni basate su dati e non su ipotesi.

Vuoi implementare Elastic APM all'interno del tuo stack?
Contattaci per una valutazione del tuo contesto e una demo su architettura reale.
FAQ
Cos’è Elastic APM e a cosa serve?
Elastic APM è una soluzione di Application Performance Monitoring che consente di monitorare le performance delle applicazioni e tracciare le transazioni end‑to‑end. Attraverso metriche, log e distributed tracing, permette di individuare colli di bottiglia, errori e rallentamenti lungo l’intero flusso applicativo, dal frontend al backend.
Qual è la differenza tra monitoring tradizionale ed observability?
Il monitoring tradizionale indica se un sistema è in stato di errore attraverso alert su soglie statiche.
L’observability, invece, consente di capire perché si verifica un problema, correlando metriche, log e trace. Il distributed tracing è l’elemento che rende osservabili i flussi applicativi complessi.
Cos’è il distributed tracing e perché è fondamentale nelle architetture moderne?
Il distributed tracing è una tecnica che permette di seguire una singola richiesta attraverso tutti i servizi di un’architettura distribuita. È fondamentale nei contesti a microservizi perché consente di identificare con precisione dove si introducono latenza ed errori lungo il flusso end‑to‑end.
Elastic APM è adatto ad ambienti enterprise e cloud‑native?
Sì, Elastic APM è progettato per ambienti enterprise, cloud‑native e a microservizi. Supporta Kubernetes, container, architetture distribuite e si integra con stack tecnologici eterogenei, offrendo visibilità e controllo anche in infrastrutture complesse.
Elastic APM supporta OpenTelemetry?
Elastic APM supporta nativamente OpenTelemetry (OTLP), lo standard CNCF per l’instrumentazione e la raccolta dei dati di observability. Questo consente di utilizzare strumentazione OpenTelemetry esistente e inviare i dati a Elastic senza dover riscrivere il codice.





